Volumes
Volumes define storage locations for your data in Embucket as database objects. A volume contains configuration settings that reference object storage systems like Amazon S3, along with access credentials and backend specifications. You create databases that use these volumes to store their tables and metadata. This document covers how to configure and manage volumes in your Embucket deployment.
Key topics covered:
- Volume types and their use cases
- Managing volumes
- Database-to-volume relationships and management
Overview
Section titled “Overview”Each volume serves as a storage configuration object that contains:
- Storage location: The object storage bucket or path where Embucket stores data
- Access credentials: Authentication information for the storage system
- Storage backend: The storage system type: S3, S3 tables bucket, filesystem, or memory
Volumes serve as the foundation for databases. Every database requires a volume to store its tables and metadata. You can reuse a single volume across many databases.
Volume types
Section titled “Volume types”Embucket supports three volume types:
S3 volumes
Section titled “S3 volumes”S3 volumes store data in S3-compatible object storage systems as database objects. S3-compatible systems use the Amazon S3 API standard for data access and management. Use S3 volumes for production deployments.
Supported storage systems:
- Amazon S3
- Any S3-compatible storage system
S3 tables volumes
Section titled “S3 tables volumes”S3 tables volumes store data in AWS S3 table buckets as database objects. Unlike standard S3 volumes that work with any S3-compatible storage, S3 tables volumes specifically integrate with AWS S3 table buckets for optimized performance. Use S3 tables volumes for AWS-native production deployments.
Supported storage systems:
- AWS S3
Filesystem volumes
Section titled “Filesystem volumes”Filesystem volumes store data on the local file system as database objects. Unlike cloud-based volumes, filesystem volumes write data directly to disk paths on the server where Embucket runs. Use filesystem volumes only for development and testing.
Memory volumes
Section titled “Memory volumes”Memory volumes store data entirely in system memory RAM as database objects. Unlike persistent storage volumes, memory volumes lose all data when the system restarts. Use memory volumes only for temporary testing.
Create a volume
Section titled “Create a volume”You can create volumes using the Embucket UI, REST API, or SQL interface. T
curl -X POST http://localhost:3000/v1/metastore/volumes \ -H "Content-Type: application/json" \ -d '{ "ident": "production-volume", "type": "s3", "bucket": "my-data-bucket", "endpoint": "https://s3.amazonaws.com", "credentials": { "credential_type": "access_key", "aws-access-key-id": "AKIAIOSFODNN7EXAMPLE", "aws-secret-access-key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY" } }'CREATE EXTERNAL VOLUME IF NOT EXISTS demo STORAGE_LOCATIONS = ((NAME = 'demo' STORAGE_PROVIDER = 's3' BUCKET = 'my-data-bucket' ENDPOINT = 'https://s3.amazonaws.com' CREDENTIALS = '{"credential_type": "access_key", "aws-access-key-id": "AKIAIOSFODNN7EXAMPLE", "aws-secret-access-key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"}'));- Navigate to the Volumes page in the Embucket UI
- Click “Create Volume”
- Enter the volume configuration details
- Click “Create”
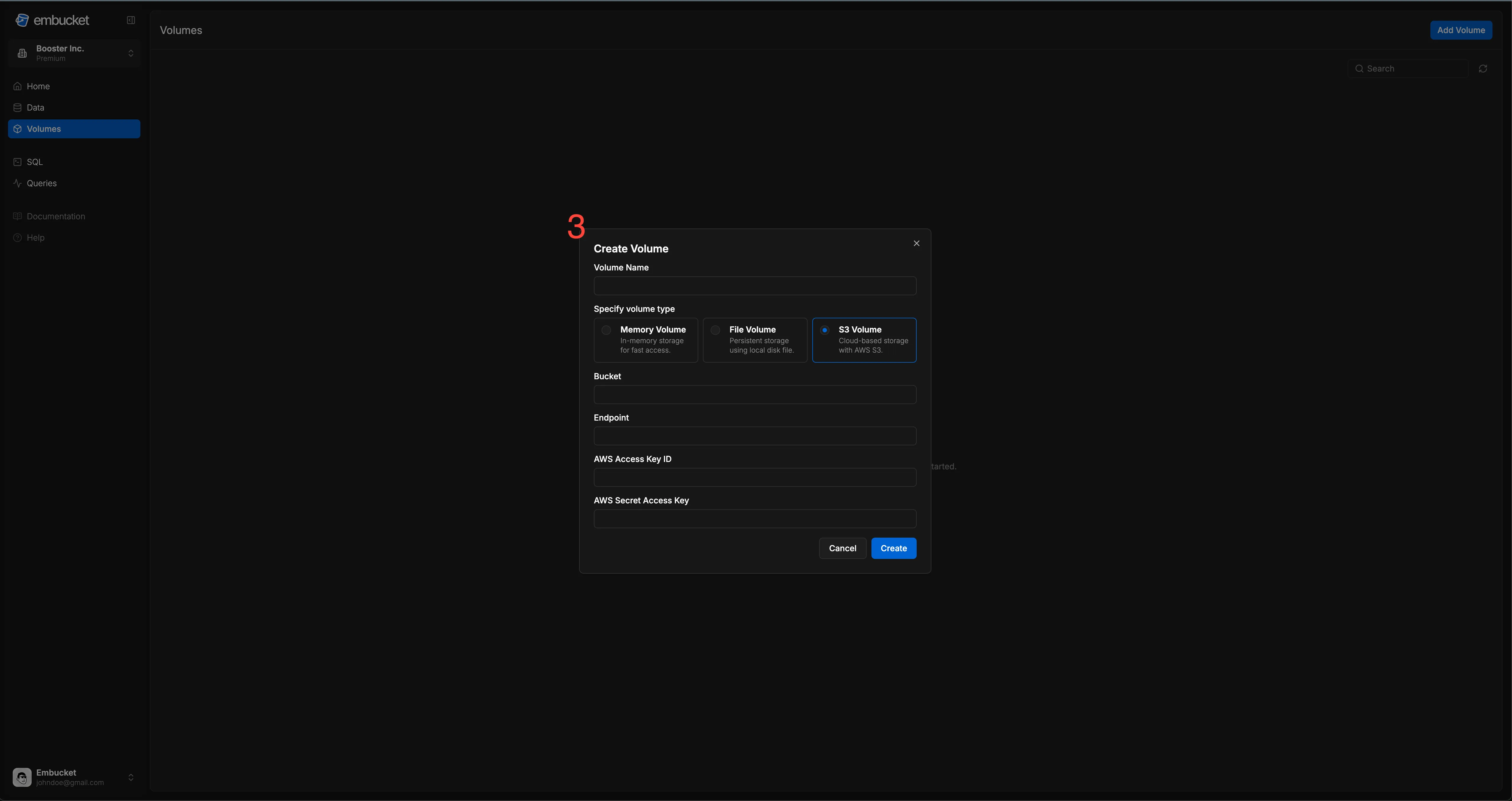
Volume attributes
Section titled “Volume attributes”Volumes require the following attributes:
ident: A unique identifier for the volumetype:memoryfor a memory volume
ident: A unique identifier for the volumetype:filefor a filesystem volumepath: The absolute path to the directory that stores data
ident: A unique identifier for the volumetype:s3for an S3 volumebucket: The name of the S3 bucket that stores dataendpoint: The S3 service endpoint (optional for AWS S3)credentials: AWS access credentials
ident: A unique identifier for the volumetype:s3-tablesfor an S3 table bucket volumecredentials: AWS access credentialsarn: The full Amazon Resource Name (ARN) of the S3 table bucket
Create database
Section titled “Create database”After creating a volume, you can create databases that use that volume to store data.
You can create a database using the REST API, SQL, or UI.
curl -X POST http://localhost:3000/v1/metastore/databases \ -H "Content-Type: application/json" \ -d '{ "ident": "analytics_db", "volume": "production-volume" }'CREATE DATABASE IF NOT EXISTS analytics_db WITH EXTERNAL_VOLUME = 'production-volume';- Navigate to the Data page in the Embucket UI
- Click “Add Database”
- Specify name and volume for the database
- Click “Create”
You can create more databases using the same volume. Each database has its own schema and tables.
Manage volumes
Section titled “Manage volumes”List volumes
Section titled “List volumes”curl http://localhost:3000/v1/metastore/volumesUpdate volume credentials
Section titled “Update volume credentials”curl -X PUT http://localhost:3000/v1/metastore/volumes/production-volume \ -H "Content-Type: application/json" \ -d '{ "credentials": { "credential_type": "access_key", "aws-access-key-id": "NEW_ACCESS_KEY", "aws-secret-access-key": "NEW_SECRET_KEY" } }'Delete a volume
Section titled “Delete a volume”curl -X DELETE http://localhost:3000/v1/metastore/volumes/volume-nameBest practices
Section titled “Best practices”Production deployments:
- Use S3 or S3 table bucket volumes for all production data
- Configure Identity and Access Management (IAM) policies with least required permissions for S3 bucket access
- Use separate volumes for different environments: production, staging, development
- Regularly backup your S3 buckets
Development and testing:
- Use filesystem or memory volumes for local development
- Use minio for development environments that need S3 compatibility
- Avoid using production volumes for testing
Volume organization:
- Create separate volumes for different data domains or teams
- Use descriptive volume names that show their purpose
- Document volume configurations and access policies