Introduction
Embucket provides Snowflake-compatible analytics with bring-your-own-cloud flexibility. Wire-compatible with Snowflake means Embucket implements Snowflake’s SQL dialect, data type system, and wire protocol. For the same query and data, Embucket produces identical results. This enables seamless migration of existing tools and workflows. You deploy a single binary that delivers familiar Snowflake SQL dialect and REST API while keeping your data in open Apache Iceberg format.
This document introduces Embucket’s core concepts, architecture, and key features. It doesn’t cover installation, configuration, or usage examples.
About Embucket
Section titled “About Embucket”Embucket provides a Snowflake-compatible lakehouse platform. A lakehouse combines the performance of traditional data warehouses with the flexibility and cost-effectiveness of data lakes using open formats.
Embucket provides the SQL interface and tooling ecosystem you already know from Snowflake. You build on an open lakehouse architecture instead of proprietary systems. Think of it as your “Snowflake bring-your-own-cloud option.” You get the same familiar developer experience. Your data stays in open formats. You maintain complete control over your infrastructure.
Embucket serves data engineers, DBAs, and data analysts. The platform eliminates traditional data platform complexity through two key innovations. First, you deploy a statically linked single binary for effortless deployment. Second, you use a zero-disk architecture—an architectural approach where compute nodes store no data locally and instead rely entirely on object storage for both data and metadata storage.
Why Embucket?
Section titled “Why Embucket?”Modern data teams face an impossible choice. You can accept the constraints of fully managed cloud lakehouses like AWS Redshift or Google BigQuery. Or you can embrace the operational complexity of building your own lakehouse stack. Embucket solves this dilemma by focusing on three core principles:
Radical simplicity: embucket’s single binary architecture eliminates complex, dependency-heavy data stacks. You move from download to query in minutes. Data teams need no external databases, no cluster management, no operational overhead. This statically linked binary contains everything required. The zero-disk architecture uses only object storage for both data and metadata.
Fanatical Snowflake compatibility: data teams leverage the ecosystem of tools built for Snowflake with bring-your-own-cloud control. You connect existing BI tools, dbt transformations, and data science workflows to Embucket with zero configuration changes. The platform accepts the exact SQL you already use. Embucket implements Snowflake’s SQL dialect and REST semantics to ensure seamless compatibility.
Open source foundation: embucket builds on proven, best-in-class open source technologies you can trust. The platform leverages Apache DataFusion for lightning-fast query execution, Apache Iceberg for ACID transactions and schema evolution, and SlateDB for metadata management. This avoids proprietary black boxes. Embucket serves as a well-integrated component in the modern open source data stack, with active contributions back to these upstream projects.
Your data stays in open formats. Compute costs remain under your control.
Key features
Section titled “Key features”Stateless compute
Section titled “Stateless compute”Stateless compute represents a computing model where servers maintain no persistent state between queries or sessions. Unlike stateful systems that store data locally, stateless compute nodes rely on external storage systems for all data persistence. Object storage and the Iceberg catalog handle durability and metadata. This architecture makes upgrades, scaling, and failover trivial.
Query-per-node architecture
Section titled “Query-per-node architecture”Query-per-node architecture enables each compute node to independently handle complete queries without requiring a separate coordinator layer. Unlike traditional distributed systems that separate coordinators from executors, each node serves as both coordinator and executor. This design eliminates single points of failure. The architecture provides better fault tolerance and simpler scaling. You add or remove nodes elastically to handle load spikes.
Snowflake-first compatibility
Section titled “Snowflake-first compatibility”Embucket implements Snowflake’s SQL dialect and REST semantics instead of inventing a new dialect. You reuse existing drivers, SDK, and workflows with minimal changes.
Apache 2.0 license
Section titled “Apache 2.0 license”Embucket uses the Apache 2.0 license as open source software.
Architecture
Section titled “Architecture”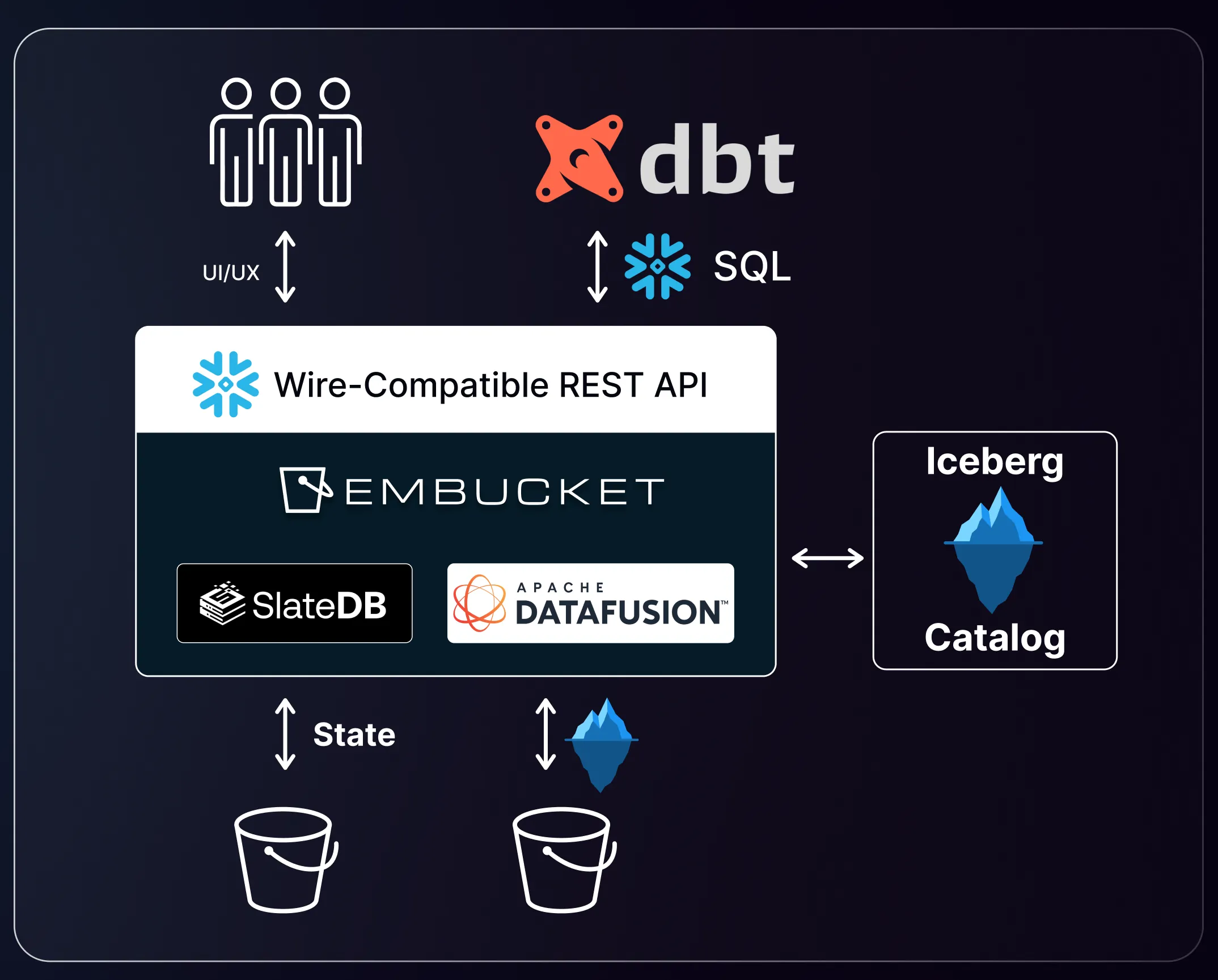
Summary
Section titled “Summary”Embucket delivers Snowflake-compatible analytics through a single binary deployment. Data teams get familiar SQL interfaces with bring-your-own-cloud flexibility. The platform uses open formats like Apache Iceberg for data storage. The zero-disk, stateless architecture simplifies operations while maintaining high performance and reliability.